Part 3 of the 600,000 Questions benchmark series
TL;DR
Comparing 10 distinct model families revealed that model architecture matters more than size for specific tasks. Phi4 at 14B achieves 95.1% on GSM8K math, matching 80B models despite being 5.7x smaller. Mistral-7B collapses to 53.1% on the same benchmark—model size alone doesn’t predict math ability. For general knowledge (MMLU), scale wins: GPT-OSS 120B leads at 87.9%, but the 80B Qwen3-Next models achieve 83.8% at much lower compute cost. The practical takeaway: match your model to your workload. For math-heavy applications, Phi4 or Qwen3-Coder punch far above their weight class. For broad knowledge tasks, bigger is still better, but the 80B tier offers the best quality-to-compute ratio currently available for local deployment.
After spending the better part of a weekend feeding questions to GPU-powered space heaters, I had accumulated enough data to answer the question that actually matters: which model should you run?
The answer, frustratingly, is “it depends.” But after 15,000+ questions per model across two distinct benchmarks, I can at least tell you what it depends on.
The Contenders
My benchmark covered 11 distinct model families:
The Qwen3 Family
- Qwen3-30B-A3B (7 quantization levels)
- Qwen3-VL-30B-A3B (AWQ 4-bit via vLLM)
- Qwen3-Next 80B (Q4_K_M and Q8_0)
- Qwen3-Coder 30B
The Competition
- GPT-OSS 20B and 120B
- Phi4 14B (default and Q8_0)
- Mistral-7B-Instruct
- Ministral-3 14B
- Devstral-Small-2 24B
- Gemma3-27B-IT-QAT
Each model ran through complete MMLU (14,042 questions) and, where time permitted, complete GSM8K (1,319 questions). No cherry-picking, no sampling, no “representative subsets.”
General Knowledge: Size Still Wins
For MMLU—the broad test of knowledge across 57 subjects from abstract algebra to world religions—model size correlates strongly with accuracy:
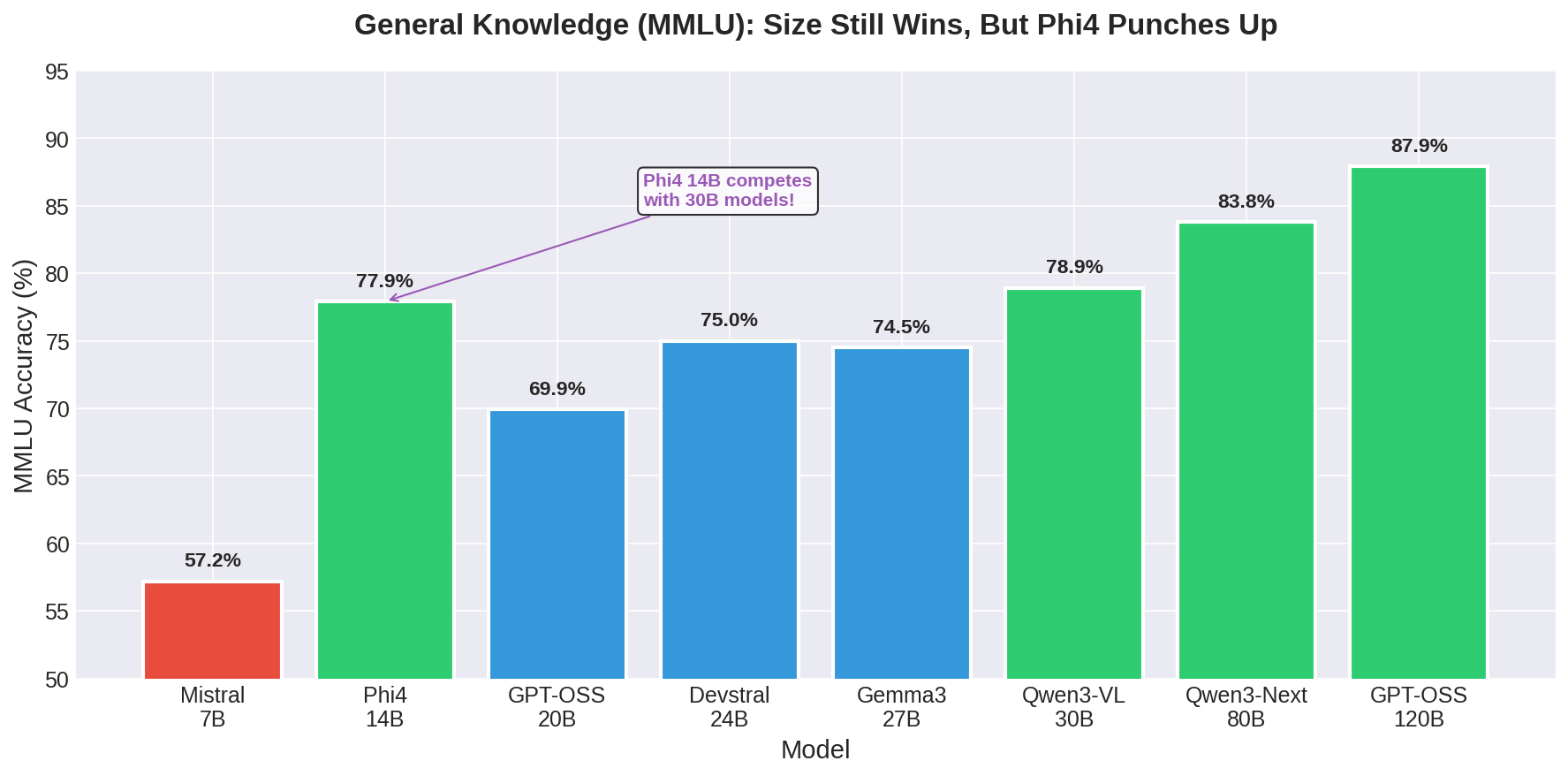
| Size Tier | Best Model | MMLU Accuracy |
|---|---|---|
| 7B | Mistral-7B | 57.2% |
| 14B | Phi4 Q8_0 | 77.9% |
| 20B | GPT-OSS | 69.9% |
| 24B | Devstral-Small-2 | 75.0% |
| 27B | Gemma3-27B-IT-QAT | 74.5% |
| 30B | Qwen3-VL AWQ | 78.9% |
| 80B | Qwen3-Next | 83.8% |
| 120B | GPT-OSS | 87.9% |
The 120B model leads, as expected. But the interesting story is in the middle of the pack.
Phi4 at 14B achieves 77.9%—competitive with 30B models despite having less than half the parameters. This suggests that training data quality and architecture innovations can substitute for raw scale, at least up to a point. Microsoft’s Phi series has consistently punched above its weight class, and these results confirm that trend continues with Phi4.
The 80B Qwen3-Next models achieve 83.8% accuracy, which represents the current sweet spot for local deployment. You get within 4 percentage points of the massive 120B model while using roughly one-third of the compute. For most applications, that’s a better trade-off than chasing the last few percentage points of accuracy.
The 20B GPT-OSS result is surprisingly weak at 69.9%. This model excels at other tasks—as we’ll see in the math results—but MMLU isn’t its strength. Not all models are created equal, and benchmark performance on one task doesn’t predict performance on others.
Math Performance: Architecture Trumps Scale
GSM8K tells a completely different story. This benchmark tests grade-school math—word problems that require multi-step reasoning but no advanced mathematics. It’s a test of logical thinking, not knowledge retrieval.
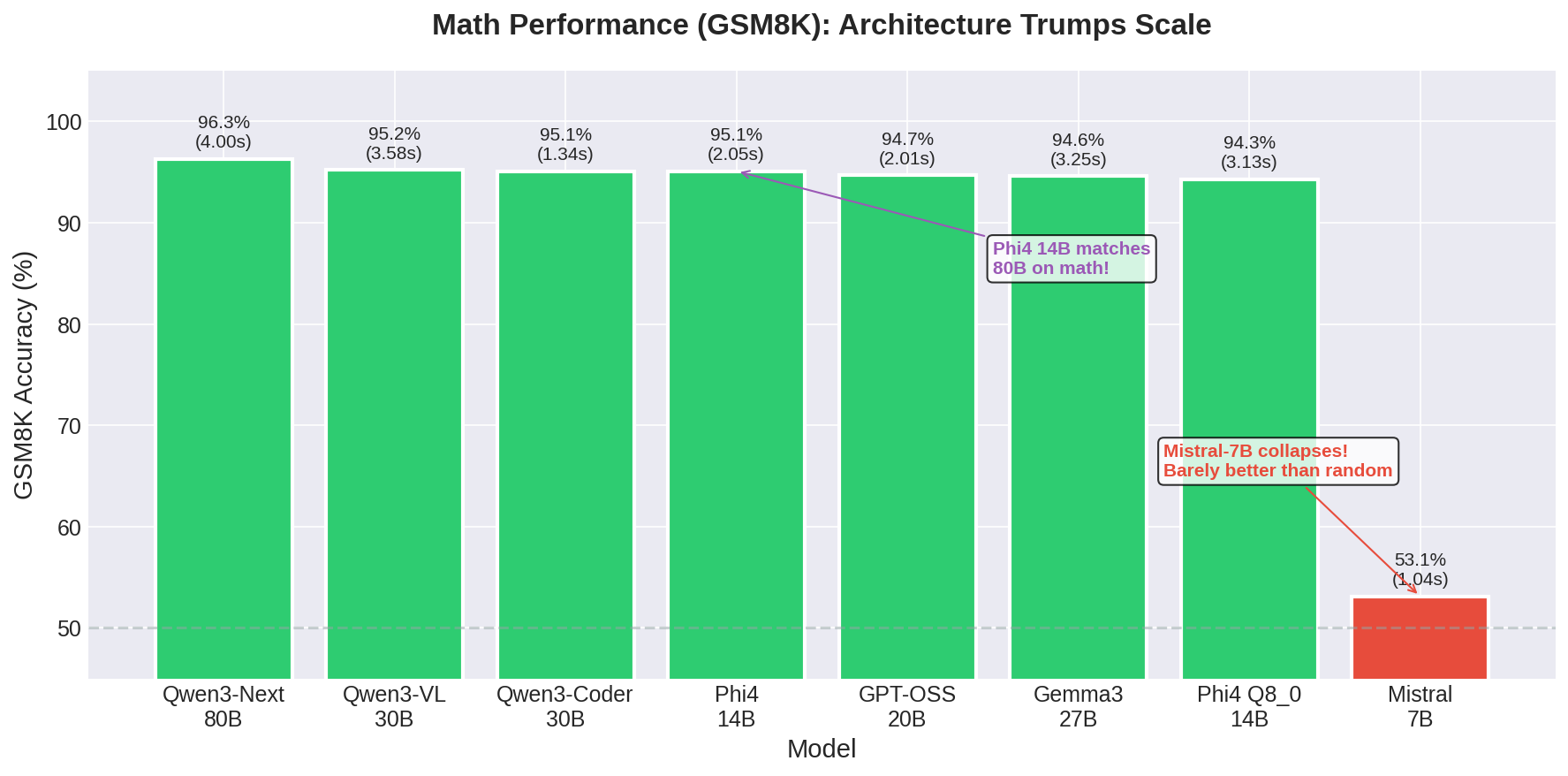
| Model | Size | GSM8K Accuracy | Time/Question |
|---|---|---|---|
| Qwen3-Next | 80B | 96.3% | 4.00s |
| Qwen3-VL AWQ | 30B | 95.2% | 3.58s |
| Qwen3-Coder | 30B | 95.1% | 1.34s |
| Phi4 | 14B | 95.1% | 2.05s |
| GPT-OSS | 20B | 94.7% | 2.01s |
| Gemma3-27B-IT-QAT | 27B | 94.6% | 3.25s |
| Phi4 Q8_0 | 14B | 94.3% | 3.13s |
| Mistral-7B | 7B | 53.1% | 1.04s |
Phi4 at 14B achieves 95.1% on GSM8K. That’s within statistical noise of the 80B Qwen3-Next at 96.3%, despite being 5.7x smaller. The Qwen3-Coder 30B hits the same 95.1% mark, as does GPT-OSS at 20B.
Then there’s Mistral-7B at 53.1%. That’s barely better than random guessing. The model can generate fluent text, answer basic questions, and handle simple instructions, but it falls apart on multi-step mathematical reasoning.
This result is important because it shatters the assumption that “bigger = better at everything.” Mistral-7B has more parameters than some models that score 95%+ on this benchmark. The architecture and training approach matter enormously for math-specific capability.
If your application involves significant mathematical reasoning—code generation, data analysis, financial calculations, scientific computing—Phi4 14B or Qwen3-Coder 30B offer exceptional value. You can run them on much more modest hardware than an 80B model while achieving nearly identical math performance.
Speed vs Accuracy Trade-offs
Here’s the full picture combining speed and accuracy for models that ran both benchmarks:
| Model | MMLU Acc | MMLU Time | GSM8K Acc | GSM8K Time |
|---|---|---|---|---|
| Qwen3-Next 80B Q8_0 | 83.8% | 0.189s | 96.3% | 3.99s |
| Qwen3-VL AWQ (vLLM) | 78.9% | 0.030s | 95.2% | 3.58s |
| Qwen3-Coder 30B | 75.3% | 0.096s | 95.1% | 1.34s |
| Phi4 14B | 77.6% | 0.455s | 95.1% | 2.05s |
| GPT-OSS 20B | 69.9% | 0.786s | 94.7% | 2.01s |
| Gemma3-27B-IT-QAT | 74.5% | 0.237s | 94.6% | 3.25s |
| Mistral-7B | 57.2% | 0.074s | 53.1% | 1.04s |
The Qwen3-Coder 30B is remarkable here. It achieves 95.1% on GSM8K in just 1.34 seconds per question—the fastest math performance by a significant margin. Its MMLU score of 75.3% is respectable though not exceptional. If your workload is math-heavy, this model offers an exceptional speed-to-accuracy ratio.
vLLM with the AWQ model dominates on MMLU speed at 0.030s per question, but its GSM8K time (3.58s) isn’t particularly fast. The concise response style that makes it fast on multiple choice hurts on problems requiring detailed reasoning.
The vLLM vs Ollama Question
I tested one model family (Qwen3-VL-30B-A3B) through both vLLM and Ollama. The comparison:
vLLM (AWQ 4-bit)
- MMLU: 78.9% accuracy, 0.030s/question
- GSM8K: 95.2% accuracy, 3.58s/question
- Response style: Concise, minimal elaboration
Ollama (FP16)
- MMLU: 78.7% accuracy, 0.129s/question
- GSM8K: Not tested at FP16
vLLM is 4.3x faster on MMLU while achieving identical accuracy. The caveat is that vLLM’s AWQ quantization was calibrated on math-heavy data (the Nemotron dataset), which may explain its strong GSM8K performance despite aggressive quantization.
For production deployments where MMLU-style question answering or classification is the primary workload, vLLM with AWQ quantization is difficult to beat. The deployment complexity is higher than Ollama, but the performance gains are substantial.
Ollama remains the easier choice for development, experimentation, and mixed workloads. The performance gap narrows on longer-form generation tasks where the concise response style of AWQ becomes less advantageous.
Practical Recommendations
Based on 150+ hours of GPU time and approximately $10 in electricity (at least I got some home heating out of it), here’s my guidance:
For General-Purpose Assistants
Use Qwen3-Next 80B Q4_K_M if you have the hardware. At 83.8% MMLU accuracy and strong math performance, it handles the widest range of tasks competently. The Q4_K_M quantization brings memory requirements down to around 50GB, making it feasible on high-end consumer hardware.
If 80B is too large, Phi4 14B offers surprising capability in a much smaller package. Its 77.9% MMLU and 95.1% GSM8K represent exceptional efficiency.
For Math and Code
Qwen3-Coder 30B is the speed champion at 1.34s per GSM8K question while maintaining 95.1% accuracy. If your application is math or code-focused and latency matters, start here.
Phi4 14B is the small model champion for math. At 14B parameters, it achieves math performance that matches models 4-6x its size.
Gemma3-27B-IT-QAT offers a compelling middle ground: 94.6% GSM8K accuracy with exceptionally consistent response times (low variance). If you need predictable latency for production deployments, Gemma3’s QAT approach delivers reliable performance without the “thinking spiral” variance seen in post-training quantized models.
Avoid Mistral-7B for any math-heavy workload. Its 53.1% GSM8K score indicates fundamental limitations in mathematical reasoning.
For Maximum Throughput
vLLM with AWQ quantization. The 0.030s per MMLU question is unmatched. If you’re processing millions of simple queries, this is your answer.
For Minimum Hardware
Qwen3-30B Q4_K_M runs in ~18.6GB of VRAM while achieving 69.1% MMLU accuracy. That’s sufficient for a single consumer GPU. Accept the accuracy trade-off or upgrade your hardware.
Mistral-7B runs on almost anything but should only be used for tasks that don’t require math or deep knowledge (creative writing, simple chat, basic summarization).
What I Learned
Running full benchmarks instead of sampled subsets revealed failure modes that smaller tests hide. The variance in quantized model response times, the non-monotonic accuracy curve across quantization levels, the dramatic performance cliffs for certain model families on certain tasks—none of this shows up when you run 100 questions and call it a day.
The local LLM ecosystem is maturing rapidly. A year ago, running an 80B model locally was exotic. Now it’s routine on prosumer hardware. The tooling (Ollama, vLLM) has become reliable. The quantization methods have become sophisticated enough that Q4 models can compete with Q8 on accuracy while being meaningfully faster.
But “bigger is better” only holds for knowledge tasks. For reasoning, architecture and training matter more than scale. A well-designed 14B model can match an 80B model on math while being dramatically faster and cheaper to run.
The space heater keeps running. The electricity bill keeps climbing. But each weekend of GPU-powered home heating produces data that actually helps make deployment decisions.
And at 450 watts continuous, it’s definitely cheaper than running the furnace.
This is Part 3 of a 5-part series. Part 4 explores how parallel queries change everything with vLLM.